
Photo by Gordon Cowie on Unsplash
この記事は pyspa Advent Calendar 2020 の 7日目の記事です。昨日は rokujyouhitoma でした。
昨年はプロダクト開発についての話を書きましたが、今年はガラッと方向性を変えて、筋トレの話をすることにします。
2019年3月からFreeleticsというAIパーソナルトレーナーアプリを使ってトレーニングを続けています。
Freeleticsについては過去にいくつか記事を書いているので、Freeleticsって何?って人は記事末尾の関連記事を読んでみてください。
さて、Freeleticsでは、複数のトレーニングを組み合わせたワークアウトを多数用意しています。それぞれに神話の神々の名前をつけていて、これらはゴッドワークアウトと呼ばれています。
このゴッドワークアウトでスターを獲得する(途中で休まず、正しいフォームでワークアウトを完走する)、そして自己ベストタイムを超えていくことがFreeleticsでの大きな目標の一つとなります。
この記事では、このゴッドワークアウトの中から代表的なものをピックアップし、紹介していきます。
誰でもすぐ試せるよう、基本的には器具なし、ランニングなしのワークアウトのみを選んでいます。(一部例外あり)
ゴッドワークアウトは初級・中級・上級の三段階にわかれているので、それぞれからいくつかピックアップして紹介していきます。
しかし、注意しなければいけないのは、この難易度分類は全く当てにならないということです。
初級なのに明らかに中級以上の負荷のものもあれば、非常に簡単なのに中級に当てはまっているものもあり、単にこの難易度分類だけを見てワークアウトを選択すると大変なことになります。
(この分類いい加減見直してほしい…)
ここではあくまで便宜上の分類だと思ってください。
可能な限り公式の動画を引用しますが、公式の動画が存在しないものについては、Freeletics上での動きと同様の動画を引用しています。
同じ名前の運動でもジムやトレーナーによって動きが微妙に違ったりしますので注意してください。
初級編
アテナ
日本でも有名な、ギリシャの守護女神アテナです。
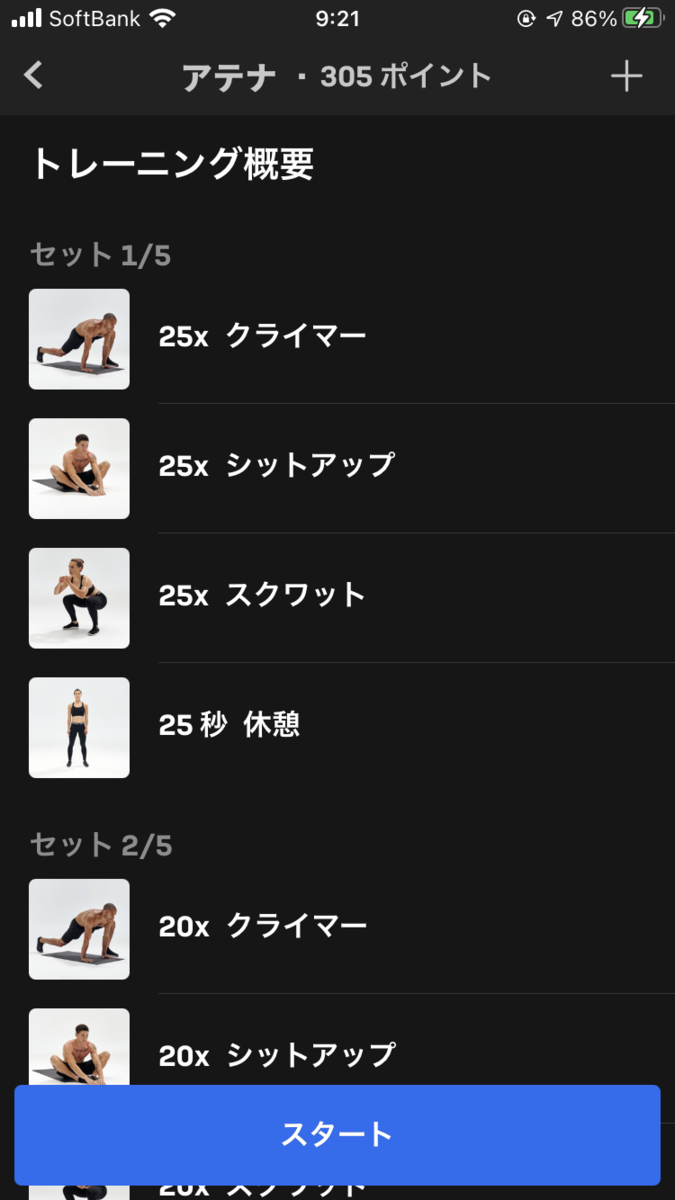
| 1セット目 | クライマー x 25 | シットアップ x 25 | スクワット x 25 | 休憩 25秒 |
|---|---|---|---|---|
| 2セット目 | クライマー x 20 | シットアップ x 20 | スクワット x 20 | 休憩 20秒 |
| 3セット目 | クライマー x 15 | シットアップ x 15 | スクワット x 15 | 休憩 15秒 |
| 4セット目 | クライマー x 10 | シットアップ x 10 | スクワット x 10 | 休憩 10秒 |
| 5セット目 | クライマー x 5 | シットアップ x 5 | スクワット x 5 |
Freeleticsを代表するワークアウトの一つです。Freeleticsユーザーで挑戦したことがない人はいないはず。
スクワットは有名なので説明は省略しますが、クライマーとシットアップという2つの運動を覚える必要があります。
クライマーは、両手をついて足を伸ばしたハイプランクの状態から、片足づつ交互に手元まで踏み込んでいくという運動です。
シットアップは、一般的な腹筋運動をさらにきつくしたものです。腹筋運動のポーズをしてから、頭の上と脚の前を両手で交互に触っていく運動です。
運動習慣がない人にとっては腹筋がめちゃくちゃきつくなります。私は、最初の2セットでお腹がつりました。しかし、Freeleticsに慣れてくるとアテナくらいの負荷はむしろ休憩に感じてくるくらい簡単に思えてきます。
モルペウス
夢の神モルペウスです。マトリックスのモーフィアスの方が有名かもしれないです。
アテナと並んで、最も有名なゴッドワークアウトの一つです。
中級に位置づけられていますが、あまりに簡単すぎるのと、内容がわかりやすいので初級編で紹介しています。
プッシュアップができるかどうかがポイントです。
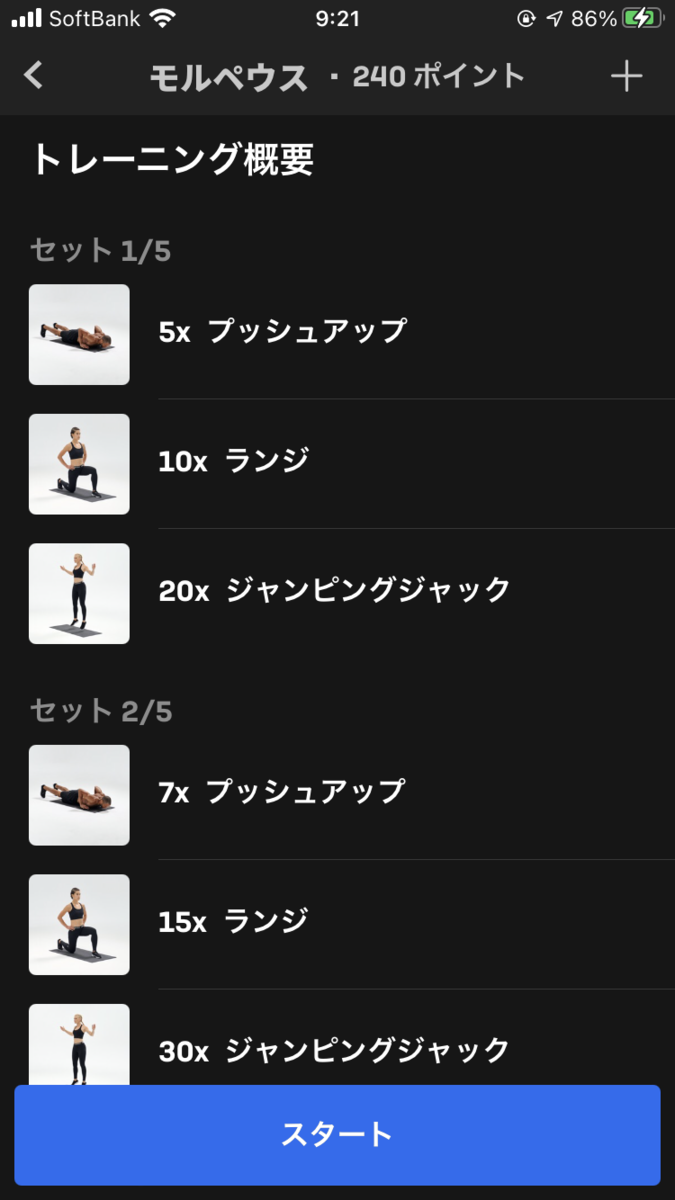
| 1セット目 | プッシュアップ x 5 | ランジ x 10 | ジャンピングジャック x 20 |
|---|---|---|---|
| 2セット目 | プッシュアップ x 7 | ランジ x 15 | ジャンピングジャック x 30 |
| 3セット目 | プッシュアップ x 10 | ランジ x 20 | ジャンピングジャック x 40 |
| 4セット目 | プッシュアップ x 7 | ランジ x 15 | ジャンピングジャック x 30 |
| 5セット目 | プッシュアップ x 5 | ランジ x 10 | ジャンピングジャック x 20 |
プッシュアップは、ご存知腕立て伏せです。Freeleticsのプッシュアップは、地面に胸をつけて両手を一度浮かせるのが特徴です。
ランジは、直立した状態から脚を交互に前に出して膝立ちの状態になる運動です。
ジャンピングジャックは、直立の状態からジャンプして両手両足を開き、その後もう一度ジャンプして脚を閉じながら両手を頭の後ろに組む運動です。ラジオ体操などでも似たような運動があるので、ほとんどの人は簡単にできるでしょう。
レイア
大地の女神レアです。
Freeleticsのゴッドワークアウトの中で最も簡単なものです。
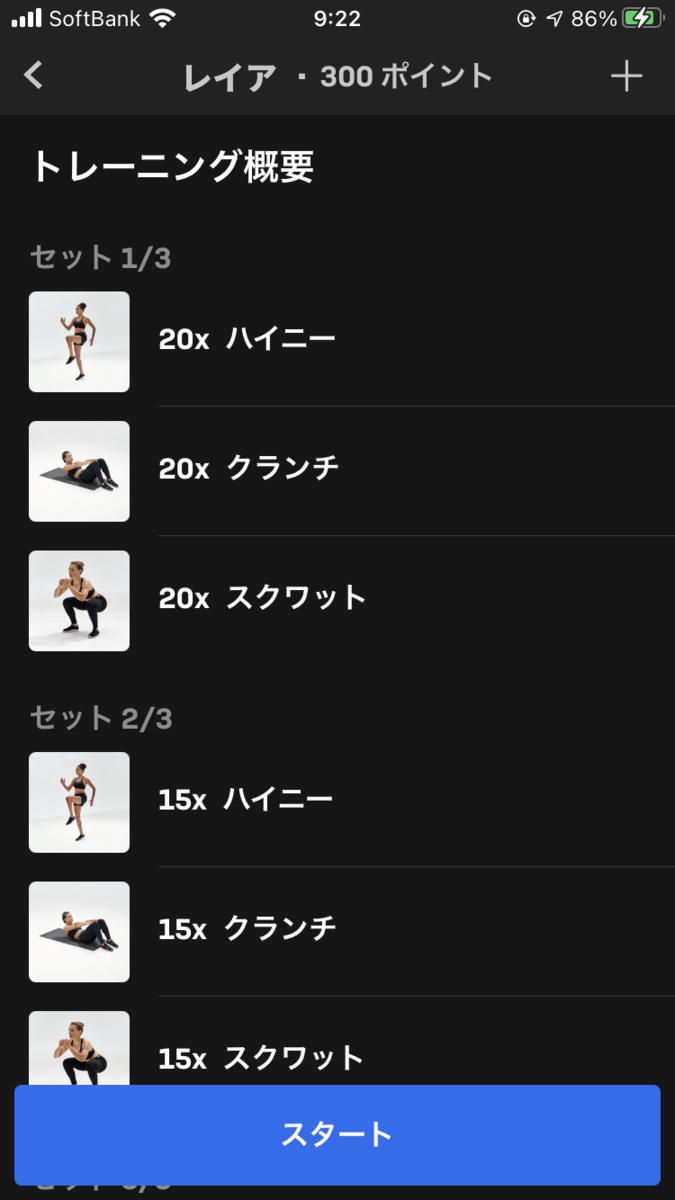
| 1セット目 | ハイニー x 20 | クランチ x 20 | スクワット x 20 |
|---|---|---|---|
| 2セット目 | ハイニー x 15 | クランチ x 15 | スクワット x 15 |
| 3セット目 | ハイニー x 10 | クランチ x 10 | スクワット x 10 |
ハイニーは、要するにもも上げです。
自分の経験上は、レイア単体で出てくることはまずなく、レイア x2 で出てきたことしかありません。それでも3分ちょっとで終わるので非常に簡単です。
メティス
知恵の女神メーティスです。
このあたりからFreeletics のヤバいメニューの紹介に移っていきます。
初級に位置付けられてますが、先に紹介したモルペウスより遥かにキツいです。
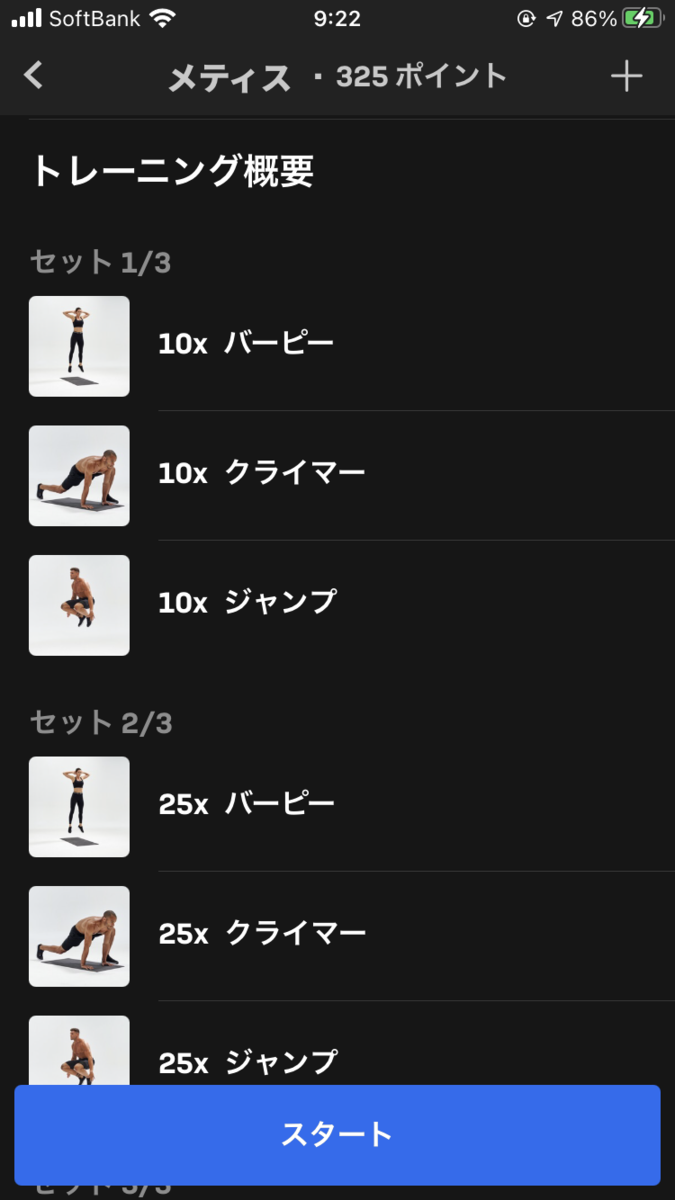
| 1セット目 | バーピー x 10 | クライマー x 10 | ジャンプ x 10 |
|---|---|---|---|
| 2セット目 | バーピー x 25 | クライマー x 25 | ジャンプ x 25 |
| 3セット目 | バーピー x 10 | クライマー x 10 | ジャンプ x 10 |
バーピーは日本でもかなり有名な有酸素運動ですが、Freeleticsでも頻繁に取り入れられています。
クライマーはアテナの項を参照してください。
ジャンプは、直立の状態から両足をジャンプさせて膝を腰の上くらいまで持ってきます。(動画は省略)
一見分量が少なくて簡単そうに見えますが、全ての運動で「脚でジャンプする」という動作が入るため脚が休む暇がなく、またバーピー→クライマーの流れではどちらも肩を使うため肩の疲労も相当なものになります。
5分間全力で両足ジャンプし続けるようなものなので、とにかく脚が持ちません。
セレネ
月の女神セレネです。
初級の中でぶっちぎりで凶悪なワークアウトです。というかこれが初級なのが本当に理解できません。
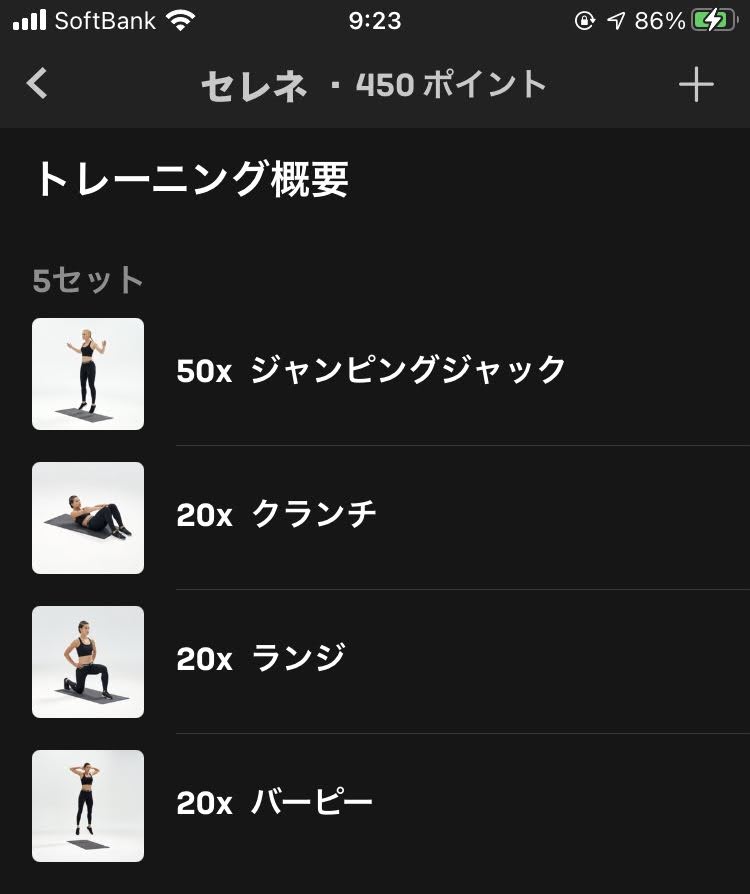
| 1セット目 | ジャンピングジャック x 50 | クランチ x 20 | ランジ x 20 | バーピー x 20 |
|---|---|---|---|---|
| 2セット目 | ジャンピングジャック x 50 | クランチ x 20 | ランジ x 20 | バーピー x 20 |
| 3セット目 | ジャンピングジャック x 50 | クランチ x 20 | ランジ x 20 | バーピー x 20 |
| 4セット目 | ジャンピングジャック x 50 | クランチ x 20 | ランジ x 20 | バーピー x 20 |
| 5セット目 | ジャンピングジャック x 50 | クランチ x 20 | ランジ x 20 | バーピー x 20 |
クランチは、多くの人がよく知る腹筋運動に一番近いです。頭の上と膝を両手で交互に触っていきます。
セレネはバーピーを合計100回行うのみならず、メティスと同様、バーピー→ジャンピングジャックの流れでジャンプ運動を連続して行うため、ジャンピングジャックでさえ凄まじくきつく感じます。
クランチだけが唯一の癒やしポイントになります。腹筋が鍛えられていないと癒やしにはなりませんが、セレネに挑戦する人がクランチ100回をできないということはまずないでしょう。
中級編
プロメテウス
火の神プロメテウスです。
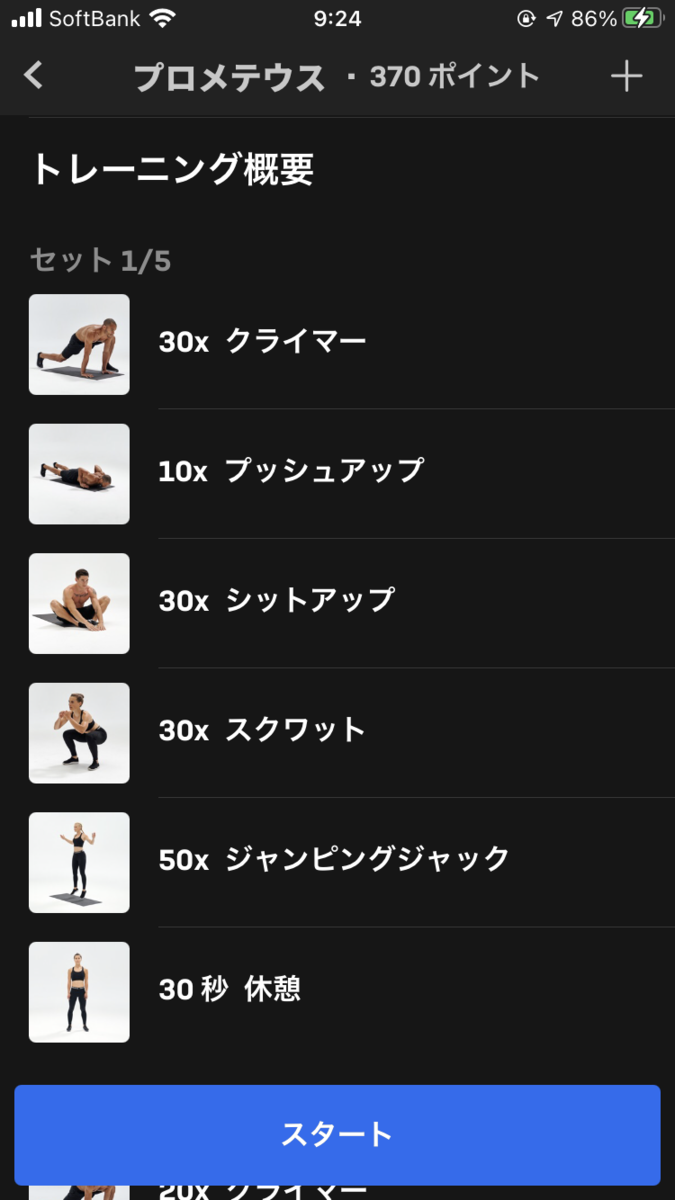
| 1セット目 | クライマー x 30 | プッシュアップ x 10 | シットアップ x 30 | スクワット x 30 | ジャンピングジャック x 50 | 休憩 30秒 |
|---|---|---|---|---|---|---|
| 2セット目 | クライマー x 20 | プッシュアップ x 7 | シットアップ x 20 | スクワット x 20 | ジャンピングジャック x 50 | 休憩 30秒 |
| 3セット目 | クライマー x 10 | プッシュアップ x 5 | シットアップ x 10 | スクワット x 10 | ジャンピングジャック x 50 | 休憩 30秒 |
| 4セット目 | クライマー x 20 | プッシュアップ x 7 | シットアップ x 20 | スクワット x 20 | ジャンピングジャック x 50 | 休憩 30秒 |
| 5セット目 | クライマー x 30 | プッシュアップ x 10 | シットアップ x 30 | スクワット x 30 | ジャンピングジャック x 50 |
アテナの上位版みたいな内容で、初級コースの大半を完走できれば問題なくできるワークアウトです。
サーキットの後半でだんだん分量が増えていくのがちょっと大変ですが、インターバルが30秒あるので非常に良心的な内容です。
アテナとモルペウスに飽きたらこれをやるのがおすすめです。
アマゾナ
このワークアウトは開発された時期が異なるのか、かなり特殊なワークアウトです。神々の名前がついていないというのも特異ですが、その内容もかなり変わっていて、このワークアウトでしか登場しない運動がいくつもあります。
全身運動が多いゴッドワークアウトの中で、ひたすら下半身に特化しているというのも特徴です。そのため、肩を痛めたときによくこれをやってました。
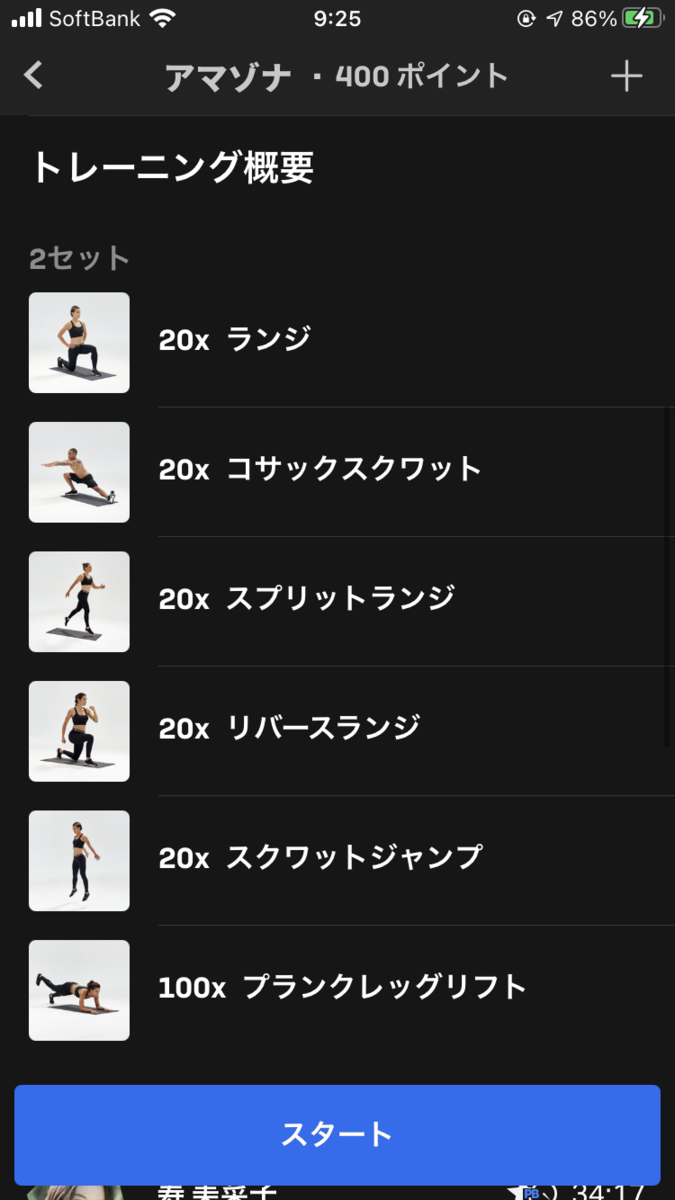
| 1セット目 | ランジ x 20 | コサックスクワット x 20 | スプリットランジ x 20 | リバースランジ x 20 | スクワットジャンプ x 20 | プランクレッグリフト x 100 |
|---|---|---|---|---|---|---|
| 2セット目 | ランジ x 20 | コサックスクワット x 20 | スプリットランジ x 20 | リバースランジ x 20 | スクワットジャンプ x 20 | プランクレッグリフト x 100 |
コサックスクワットは、片足を伸ばし、もう片足を曲げる、屈伸運動のような動作をする片足スクワットです。見た目は簡単そうですがかなり負荷のある運動です。
スプリットランジは、ランジの格好からジャンプして脚を交互に入れ替える運動です。ジャンプ運動なのでかなり脚に負荷がかかります。
リバースランジは、ランジの逆で、膝をつく方の脚を後ろに出し、膝を立てる方の脚をその場に残してランジします。
スクワットジャンプは、スクワットして膝を曲げた後に伸ばしてジャンプする運動です。これもジャンプ運動でかなり負荷がかかります。
プランクレッグリフトは、プランクの状態で交互に脚を上げる運動です。
連続して大腿筋に負荷をかけていくので、後半のスクワットジャンプとプランクレッグリフトがかなりきつくなります。インターバルがないので、2セット目は特にきついです。
アフロディテ
愛と美の女神アフロディーテです。最近はなくなりましたが、昔のFreeleticsのアプリの更新履歴には「アフロディテが終わるより早くバグ対応します!」と書かれていたりしました。
内容もとてもシンプルで、Freeleticsを代表するワークアウトの一つです。
あまりにきつすぎて私はまだ挑戦したことありませんが。
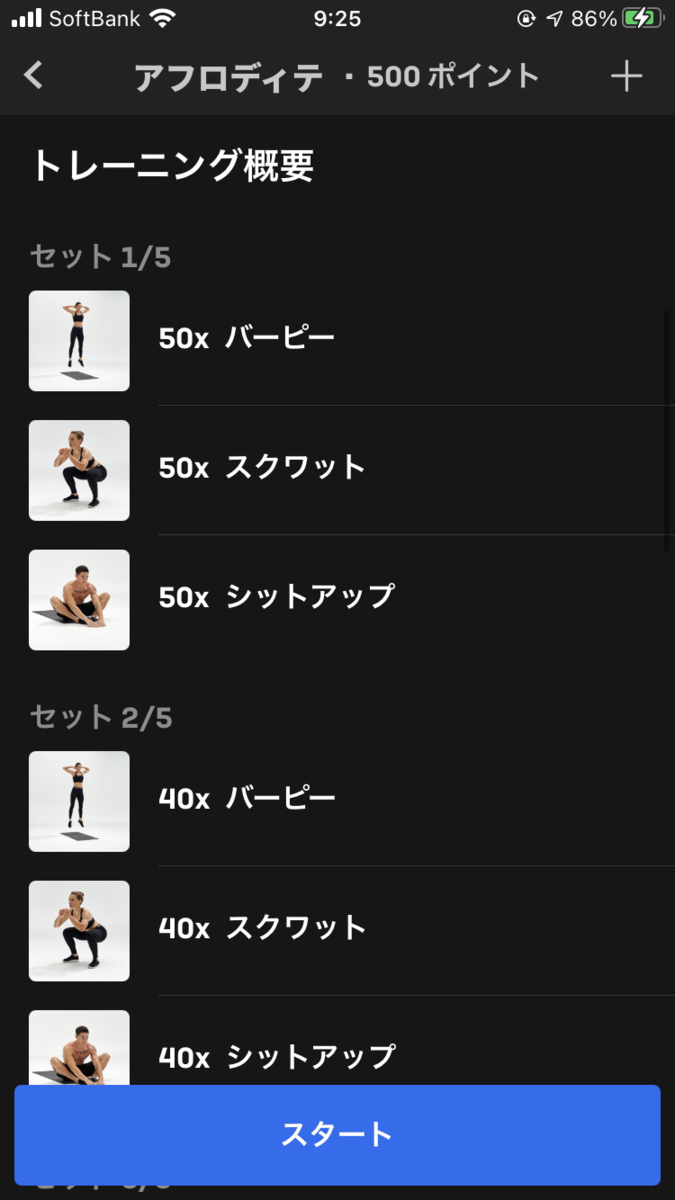
| 1セット目 | バーピー x 50 | スクワット x 50 | シットアップ x 50 |
|---|---|---|---|
| 2セット目 | バーピー x 40 | スクワット x 40 | シットアップ x 40 |
| 3セット目 | バーピー x 30 | スクワット x 30 | シットアップ x 30 |
| 4セット目 | バーピー x 20 | スクワット x 20 | シットアップ x 20 |
| 5セット目 | バーピー x 10 | スクワット x 10 | シットアップ x 10 |
バーピー→スクワット→シットアップのサーキットをインターバルなしでそれぞれ150回づつ行うというもの。初級最難関のセレネでさえバーピー100回やクランチ100回なので、アフロディテがどれだけ凶悪かおわかりでしょうか。
リーダーボードを見てみると、上級者達はこのアフロディテを15分以下で完走してます。
上級編
ここから先は私もほぼ未踏の領域です。(ハーフセット等は挑戦したことあるけどフルセットはほぼ未体験)
ヘカテ
冥界の女神ヘカテーです。
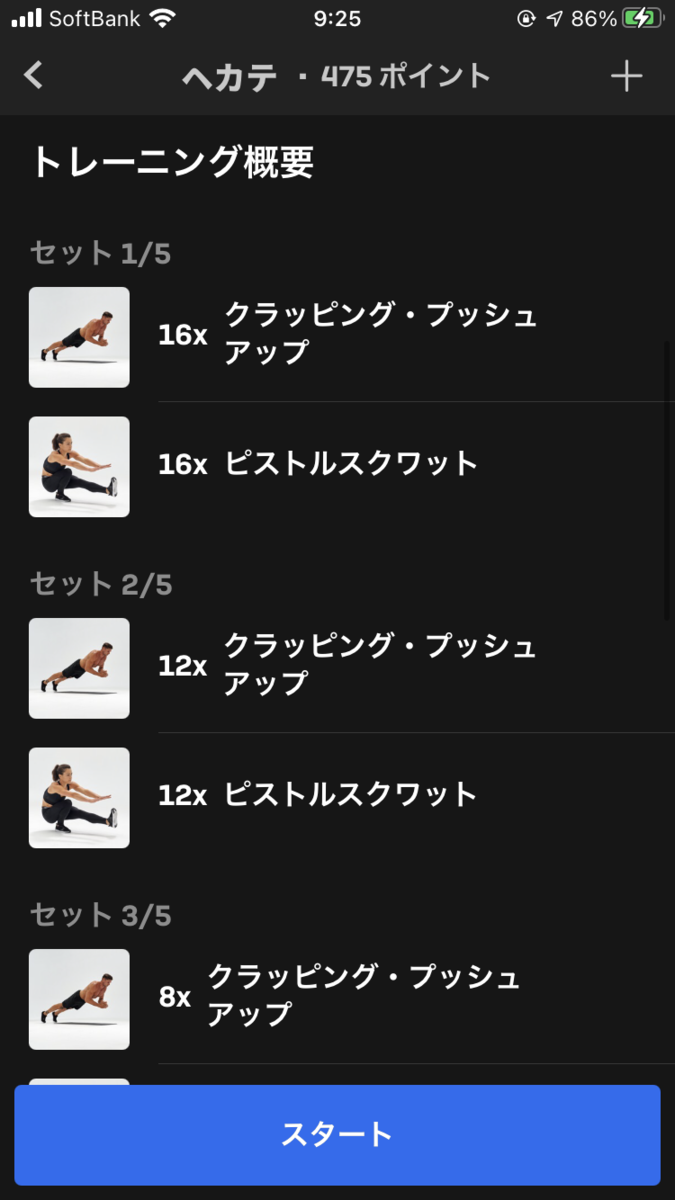
| 1セット目 | クラッピングプッシュアップ x 16 | ピストルスクワット x 16 |
|---|---|---|
| 1セット目 | クラッピングプッシュアップ x 12 | ピストルスクワット x 12 |
| 1セット目 | クラッピングプッシュアップ x 8 | ピストルスクワット x 8 |
| 1セット目 | クラッピングプッシュアップ x 6 | ピストルスクワット x 6 |
| 1セット目 | クラッピングプッシュアップ x 4 | ピストルスクワット x 4 |
クラッピングプッシュアップは、プッシュアップの上位版で、腕を伸ばす代わりに腕でジャンプして拍手するというものです。
ピストルスクワットは要するに片足スクワットです。脚への負荷も相当なものですが、バランスを取るのがとても難しい運動です。
どちらも肘・肩と膝にものすごい負荷がかかるので、よほど筋力に自信がない限りやめた方がいいです。
一方で心肺機能としての負荷はそこまで高くないので、筋力が十分あれば上級の中では比較的とっつきやすいのではないかと思います。(といいつつ私はまだフルセット未チャレンジですが)
ケルベロス
地獄の番犬ケルベロスです。ひたすらプランクを行うワークアウトで、その姿勢が四つん這いなのでケルベロス(=犬)の名前をつけたのではないかと思います。
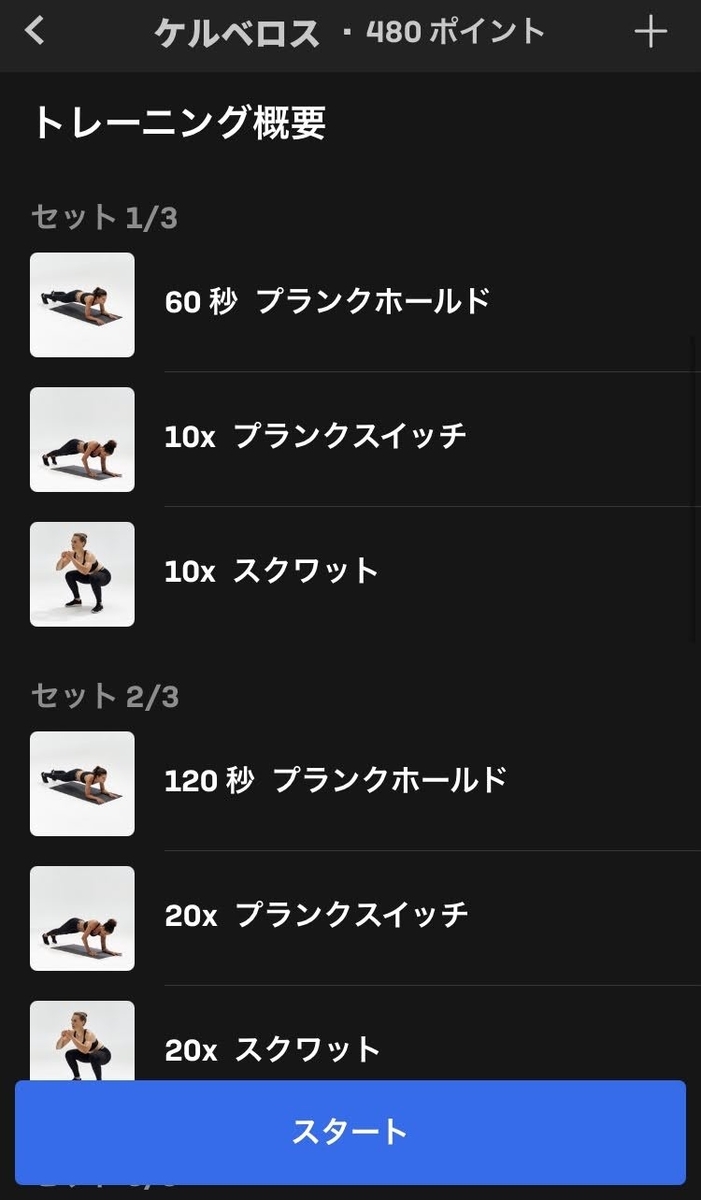
| 1セット目 | プランクホールド 60秒 | プランクスイッチ x 10 | スクワット x10 |
|---|---|---|---|
| 2セット目 | プランクホールド 120秒 | プランクスイッチ x 20 | スクワット x 20 |
| 3セット目 | プランクホールド 180秒 | プランクスイッチ x 30 | スクワット x 30 |
プランクスイッチは、ハイプランクの状態から肩肘づつ曲げていきロープランクの状態に移り、そこからまた肩肘づつ伸ばしてハイプランクの状態に戻るという運動です。
アプリ内の説明動画では、昔はロープランク→ハイプランク→ロープランクという運動だったのですが、最近のアップデートで説明動画が更新されると、なぜかハイプランク→ロープランク→ハイプランクという動作になりました。以下の動画は旧バージョンの動きなので注意してください。
とにかくプランクホールド合計6分間がきついです。この間なにもできずにじっとしてるだけなので肉体的のみならず精神的にもきついです。プランクホールドが終わった直後のプランクスイッチもきついです。スクワット合計60回は完全におまけです。
ウェヌス
愛と美の女神ヴィーナスです。ギリシャ神話の神々の名前が多く用いられる中、ウェヌスは珍しくローマ神話からの引用です。アフロディテの別名とも言われています。
メニューもアフロディテと同様にとてもシンプルです。
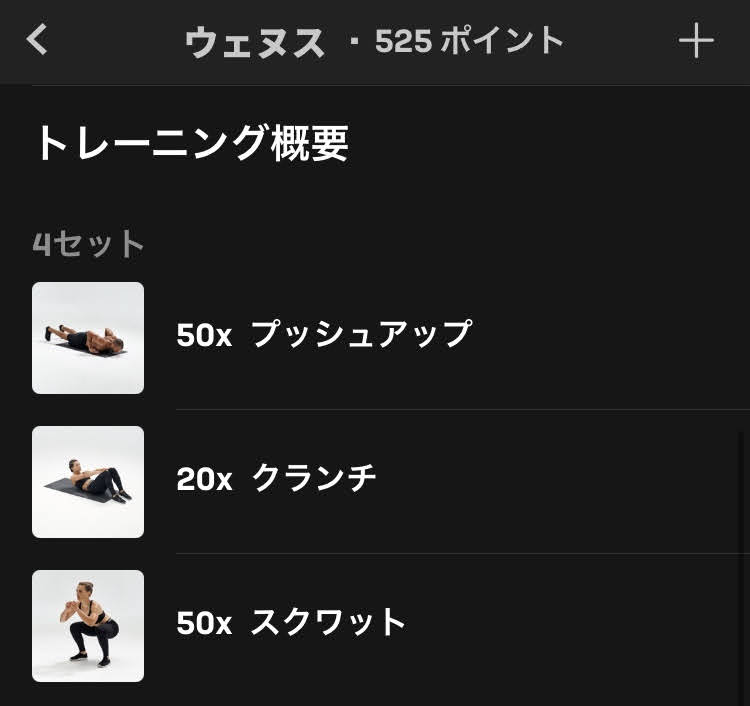
| 1セット目 | プッシュアップ x 50 | クランチ x 20 | スクワット x 50 |
|---|---|---|---|
| 2セット目 | プッシュアップ x 50 | クランチ x 20 | スクワット x 50 |
| 3セット目 | プッシュアップ x 50 | クランチ x 20 | スクワット x 50 |
| 4セット目 | プッシュアップ x 50 | クランチ x 20 | スクワット x 50 |
つまり、腕立て200回腹筋80回スクワット200回をやるだけ。とてもシンプルです。腕立て50回 x 4セットをインターバルなしでできる人なら問題ないはず。私はできません。
ヘリオス
太陽神ヘリオスです。おそらくランニングなし + 器具なしのゴッドワークアウトの中では最難関と思われます。
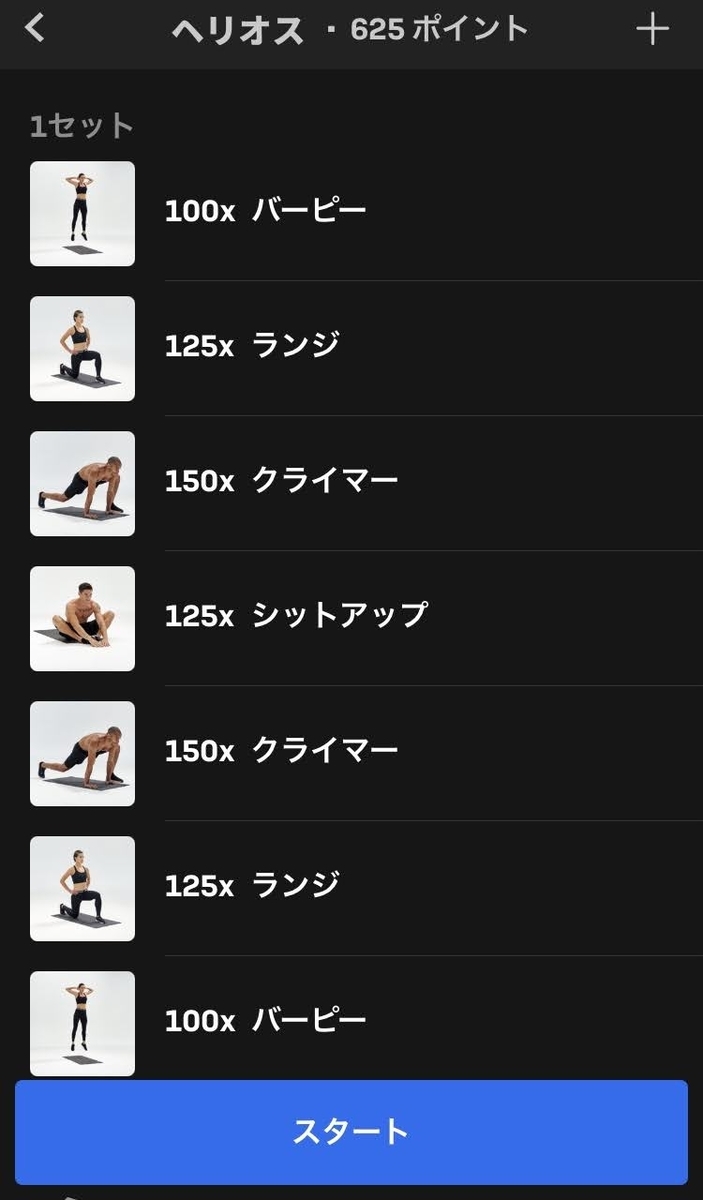
| 1セット目 | バーピー x 100 | ランジ x 125 | クライマー x 150 | シットアップ x 125 | クライマー x 150 | ランジ x 125 | バーピー x 100 |
|---|
なんと1セットのみ。別に変わった運動が入るわけでもなく、シンプルに分量が膨大なワークアウトとなっています。
バーピー200回、ランジ250回、クライマー300回、シットアップ125回をインターバルなしで走り切るのは相当な身体能力が要求されます。
リーダーボードを見ると、上級者はこの内容を30分以下で完走しています。恐ろしい…。
ゼウス (器具あり最難関)
ご存知、全能の神ゼウスです。ゼウスの名を冠するだけあってその難易度もかなりのものなので、参考までに紹介しておきます。
倒立するための壁と、懸垂をするためのバーが必要になります。
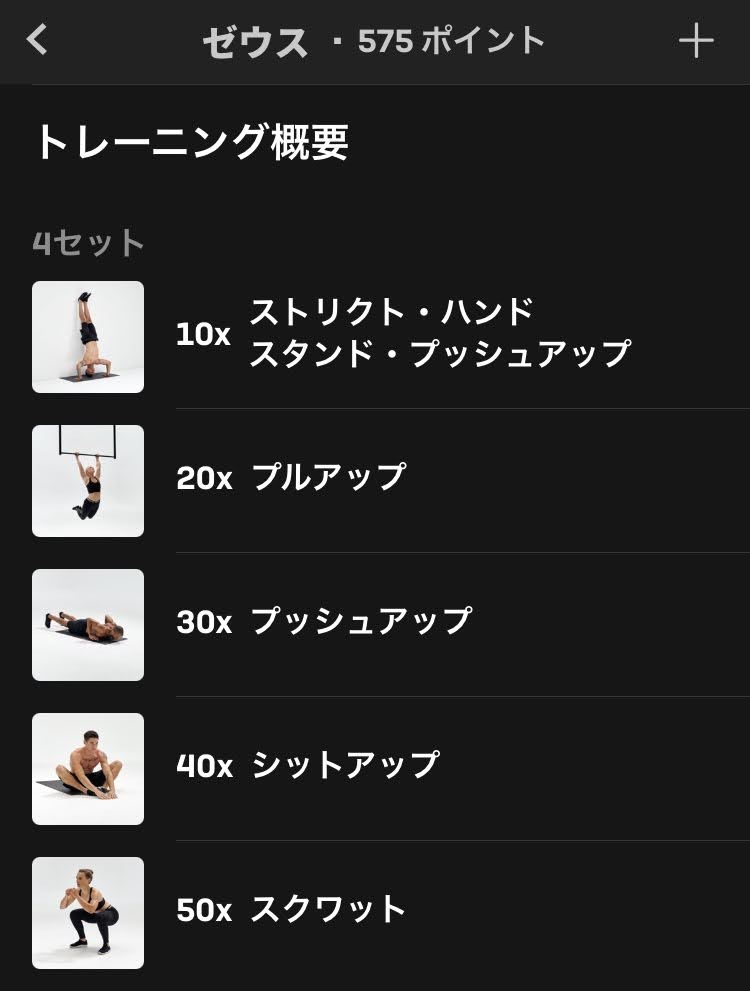
| 1セット目 | ストリクトハンドスタンドプッシュアップ x 10 | プルアップ x 20 | プッシュアップ x 30 | シットアップ x 40 | スクワット x 50 |
|---|---|---|---|---|---|
| 2セット目 | ストリクトハンドスタンドプッシュアップ x 10 | プルアップ x 20 | プッシュアップ x 30 | シットアップ x 40 | スクワット x 50 |
| 3セット目 | ストリクトハンドスタンドプッシュアップ x 10 | プルアップ x 20 | プッシュアップ x 30 | シットアップ x 40 | スクワット x 50 |
| 4セット目 | ストリクトハンドスタンドプッシュアップ x 10 | プルアップ x 20 | プッシュアップ x 30 | シットアップ x 40 | スクワット x 50 |
ストリクトハンドスタンドプッシュアップは、要するに壁を使った逆立ち腕立て伏せです。
プルアップは、反動を使った懸垂です。ちなみに私はハーフラックで懸垂を行っているので反動を使うとさすがにひっくり返るため、プルアップは全て反動なしで行っています(その方が効く)。
まず、逆立ち腕立てができない人は門前払いです。できたとしても、逆立ち腕立て→懸垂→腕立てを連続して行うのはかなりの強靭な肉体がないと厳しいでしょう。
さらなる高みを目指して
ゴッドワークアウト1セットでは物足りない、という人たち向けに、Freeleticsでは最大3セットまでゴッドワークアウトを連続実行できるようになっています。
リーダーボードを見ると、ヘリオス3セットを完走している人が何人かいます。恐ろしい体力です…。
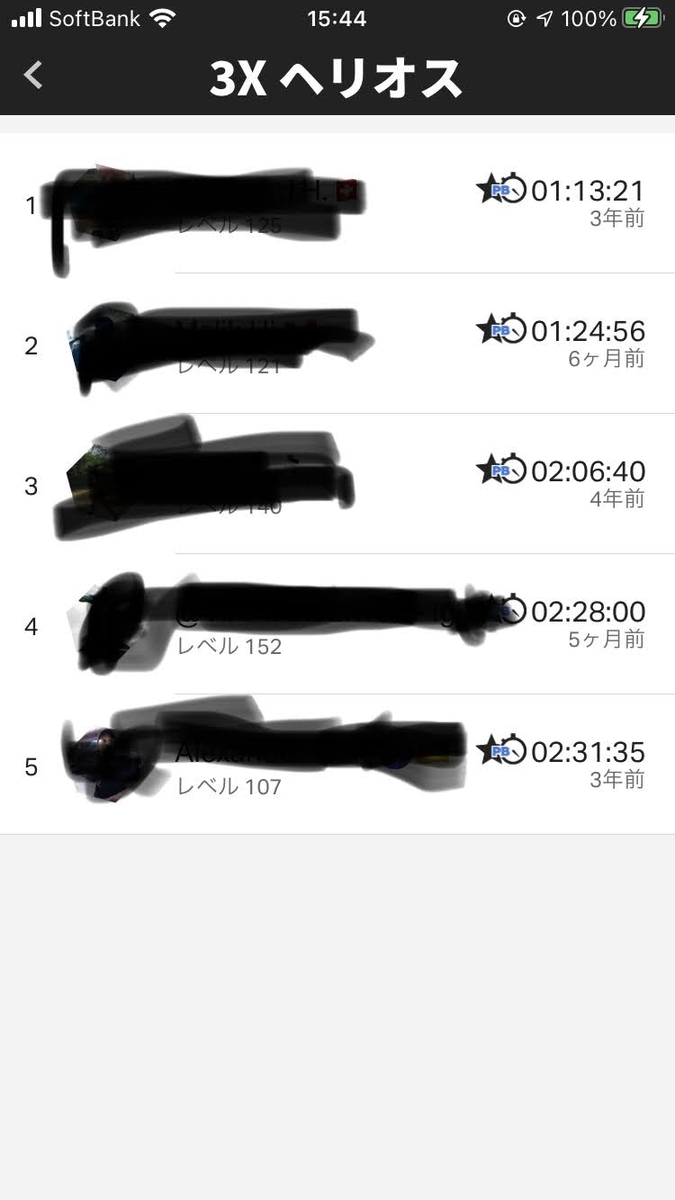
こんなんできるか!
はい、初級はともかく中級以上でフルセットやるのは普通の人にはまず無理です。
実際のFreeleticsでは部分セットだけをメニューに組み込むなど、アスリートの身体能力に合わせたメニューを用意してくれるので安心してください。
(例えば「セレネ 1セット目のみ」「ケルベロス 1セット目のみ」など)
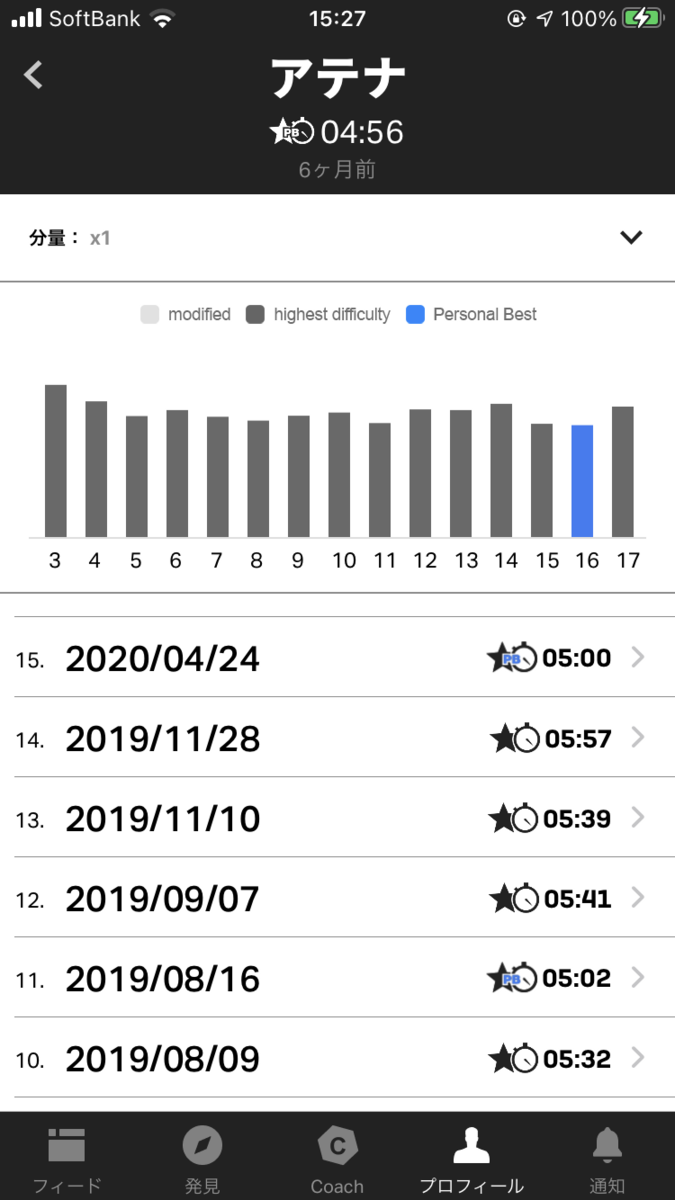
ですが、部分セットだけをこなしても記録の見直しができないので、やっぱりフルセットできるようになる方が楽しいです。フルセットのゴッドワークアウトをこなすと、以下のようなログに記録が残ります。
Freeleticsに興味を持った人へ
Freeleticsは有料のアプリです。年間1万円のサブスクリプションです。
3ヶ月プランや6ヶ月プランもあるので、続ける自信がないという人はこちらを購入してもいいです。14日間は返金に応じてくれるので、試しに買ってみて、合わなかったら返金しましょう。
Freeleticsを始めてみたいという人は、下記のリンクから購入すれば20%オフで買えます。 Coach と Nutrition (食生活改善)の二種類が出てきますが、Nutrition は自分は試していません。運動だけなら Coach で十分と思いますが、誰か Nutrition を試した人がいたら感想教えてください。
pyspaアドベントカレンダーの次回予告
明日は、Freeleticsのゴッドワークアウトなんて鼻歌交じりに完走できるほど屈強な肉体を手に入れてしまった ymotongpoo です。











![[ミズノ] トレーニングウェア 半袖Tシャツ ナビドライ Uネック 吸汗速乾 メンズ 32JA6150 14 ドレスネイビー×ホワイト M](https://m.media-amazon.com/images/I/41OYL8JUQPL.jpg "[ミズノ] トレーニングウェア 半袖Tシャツ ナビドライ Uネック 吸汗速乾 メンズ 32JA6150 14 ドレスネイビー×ホワイト M")

![Fitbit Charge4 Special Edition GPS搭載フィットネストラッカー Black/Charcoal Woven L/Sサイズ [日本正規品] FB417BKGY-FRCJK](https://m.media-amazon.com/images/I/41eu0096qnL.jpg "Fitbit Charge4 Special Edition GPS搭載フィットネストラッカー Black/Charcoal Woven L/Sサイズ [日本正規品] FB417BKGY-FRCJK")

